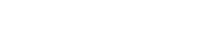

-
5 development principles we strive for at Mixlr
We're hiring. If you enjoy this post, you might enjoy being part of our team too. Visit the Mixlr jobs homepage.
Since we started Mixlr over five years ago, we’ve experimented with a lot of different approaches to development.
Here are five principles that we’ve found particularly valuable over that time.
Release early and often. (Even if it’s not perfect yet.)
This is the first rule of the Agile manifesto, but arguably the most important - and even more so when you’ve got a small team, and a big user base.
The Mixlr community has over 45,000 monthly active broadcasters and millions of monthly listeners.
To keep everybody satisfied, we have little choice but to aim to release features and improvements frequently, despite our small team size.
We start at the product design phase, defining clear user stories at the earliest possible opportunity, and then stick with them throughout the development cycle. This helps us to focus on improvements that our users really want, and avoid wasted development time.
When it comes to release, we always favour pushing new code as early as possible.
This doesn’t mean that allowing a user’s experience to regress is acceptable, of course. We make careful use of tools like Google Analytics, Mixpanel, Browserstack and Airbrake to be sure that won’t happen.
But with these safeguards in place, we can allow our community to benefit from new features quickly — even if they’re not quite pixel perfect yet.
And with early release comes early dialog too, which helps us finetune and improve a feature more efficiently than we ever could in a closed QA environment.
Readability counts.
Once again, Mixlr’s ultra-low ratio of developers to active users makes this principle crucial for us.
Code is nothing if it isn’t readable — and readable by others, not just the original developer.
Once again, there’s no simple way to achieve this.
Why write a nested ternary statement, when you can space that logic out onto half-a-dozen lines and make it pulse with clarity and simplicity?
When writing Ruby, is that early return statement triggered by a dangling conditional worth sacrificing a clear, fully-indented code path that can be understood at a glance?
Can that variable really not be named a little more descriptively?
These are questions we try to ask of every commit, because if we can create code that’s easy to read, then we’ve probably built something that’s easy to maintain too. And everybody, including our users, benefits from that in the long-run.
Keep the code visible.
As Linus’s Law states, enough eyeballs make all bugs shallow.
We try to learn from this at Mixlr in a couple of ways.
Firstly, by encouraging our team to review each other’s code on an adhoc basis. Once again, Slack is a great tool here, integrating closely with Github to make the code we commit visible to everybody within seconds.
And secondly, by enabling more formal code reviews and pair programming opportunities whenever possible.
Apart from directly increasing overall code quality, this also all has the advantage of exposing more of our backend infrastructure to our team, which is a great learning opportunity too.
If it moves, test it.
Writing automated tests isn’t just about ensuring the code you’re writing right now is solid. It also tends to bring a number of other potential benefits to a project.
For starters, it’s possible to move much, much faster when you’re confident that the changes you’re making have left other parts of an application unaffected. So our users benefit now, and then time and again later too.
Unit testing also naturally tends to engender modular, easy-to-understand code — something which helps improve the long-term maintainability of a project in ways which are difficult to foresee.
Our Ruby on Rails applications feature comprehensive test suites, and with the help of Jenkins and Slack we keep them at the heart of our day-to-day process.
Deployments are frictionless.
If we’re going to release early and often, then we’d better make sure that our deploy process allows it.
We use Capistrano for all of our main projects, which gives us a common deployment interface that our entire development team is familiar with.
During a recent upgrade to Capistrano 3, we also refactored and modularised all of our deploy hooks, making the system significantly easier to understand and modify.
We use Matt Brictson’s Airbrussh gem to prettify and improve the coherence of the Capistrano output.
Our internal staging site provides us an ideal environment for testing and otherwise experimenting with the deploy process, and tight integration with Slack means that our team always knows who is deploying what to where.
All of this means that our entire team is comfortable with deploying to production (often from their very first day with us), so we can fix bugs quicker and deploy new features more readily than we would otherwise be able to.
Read more: How to deploy software
-
Five ways to use Slack part two: How we made Campfire sounds work in Slack
In this post we show you how Mixlr pushes Slack beyond its boundaries; how we let the genie out of the bottle–into the office. Before Mixlr got addicted to Slack we used Campfire. One of the features that made Campfire, the real-time communication tool for team collaboration, indistinguishable is the feature to play sounds to everyone. From sounds like Danger Zone from Topgun, over George Takei’s Oh My, to Ludacris’ Roll Out, there is a sound to emphasise every kind of situation; be it a colleague spilling coffee over your laptop or a successful rollout of a new feature.
After Mixlr migrated to Slack we found ourselves becoming more and more productive with every new integration we added. The lack of sounds though, was a wound which would not heal. We take great pride in our office stereo as it not only enables us to listen to music, share new discoveries but also use our product in a communal way. With a Raspberry Pi available in the office, this screamed out for an office hack!

Buy it, plug it, play it
The Raspberry Pi is a credit card–sized single-board computer developed with the intent to promote the teaching of basic computer science in schools and developing countries. It has gained popularity as a supplementing device especially due to its size and low amount of power demand hence making it ideal for interacting with the environment.
The plan was to connect the Raspberry Pi to our speakers to play sounds from it. Our speakers are set up through a mix deck which means it would be just a matter of connecting the Raspberry Pi to it in order to make any output sounds available while maintaining our office music sounds.
Slack allows you to define outgoing webhooks or even slash commands. For instance, you could define the following command:
/sound [name]After that you need to tell Slack to which endpoint it should post the data as soon as someone enters the command. Maybe you can already guess how everything fits together.
We let Slack post that message directly to our Raspberry Pi which then in turn would trigger the sounds using
mpg123.path = config.SoundsDir + track + ".mp3" cmd := exec.Command("mpg123", path) go cmd.Run() message := fmt.Sprintf(":speaker: *%s* is playing _%s_", user, track) sendChatResponse(message, channel)For that we built a web server Huck 9000 (name inspired by our patron saint Mick Hucknall) using Go which parses the different HTTP messages and translates them into Linux commands to be executed on the Raspberry Pi.
It is such a simple setup but if you think about it opens up so many possibilities in terms of extensibility: setting up a timer to play coffee sounds when the brew is done, connecting it to our office TV and show a random GIF on every
/giphyor even detecting the song which is currently played on the speakers and posting it back to Slack. We already use it to gather everyone for our daily standup:
Feel free to take a look at the implementation as we have open sourced the code. Clearly, these are just simple and fun things but they enable you to think in a creative way about your workplace and even though it does not directly improve our product it heavily improves our day to day happiness and you never know when one of these hacks lead to another innovative idea as well.
-
5 ways we work as a team at Mixlr
We're hiring. If you enjoy reading this post, you'll find Mixlr is a great team to be a part of. Visit the Mixlr jobs homepage.
At Mixlr, we’ve racked up more than five years of experience working as a team to create our service.
Along the way, we’ve also accumulated a few methods that help us work together effectively as a team on a day-to-day basis. Here are some of our favourites.
Daily standup
A standup is one of the most commonly known agile methodologies. Everybody in the team comes together for a few minutes, to recap what they worked on yesterday, and what they’re planning to work on today.
We find it’s a great start to the day for a few reasons.
Firstly, it ensures that everybody’s first act of the day involves communicating with the whole group, which we find helps get the day off to a positive start.
Secondly, it’s an easy way for everybody to keep track of what others are working on. If a team member is unable to proceed with their task-in-hand for some reason, then the standup helps unblocking to happen naturally.
After some previous attempts, we’ve settled for now on a simple format that works well for us. For reasons too archaic to pin down, a generous and not remotely ironic dose of Mick Hucknall is involved.
In-office sound effects
We use Slack for group chat at Mixlr, ever since migrating away from the erstwhile number one Campfire.
Slack has proven more useful, and infinitely more addictive, but there’s one thing we sorely missed - Campfire’s sound effects.
There’s nothing like being able to drop a creative sad trombone into conversation to help make one’s point. So we decided to act.
Our team member Konrad — with the help of a Raspberry Pi, the Go programming language and Slack’s command API — built an ingenious custom sound effects system that allows any of our team to use Slack to trigger a library of custom sound effects over the office sound system.
And it works… amazingly well.
We now have not only the Campfire sound library, but an ever-growing cumulation of custom sounds too.

1-to-1s
Every fortnight, each member of the Mixlr team gets out of the office and spends a scheduled hour one-to-one with their first-contact manager.
The subject of the meeting varies, and is ultimately up to the team member: it’s their time to discuss on-going projects, vent about any frustrations they may have, and ask questions about anything and everything.
We’re still in the early days of our adoption of regular 1-to-1s, but we’re already seeing some profoundly positive benefits: new lines of communication being opened up, and interesting and valuable discussions which quite likely would otherwise never have occurred.
There’s no doubt that 1-to-1s will be an important part of our process going forward.
Real-time customer milestones
It’s a nice feeling when the work you’ve done has led to a new customer signing up, or a user sending us an positive email.
We try to make the most of this by having key customer milestones posted automatically into Slack.
When a customer signs up or renews their subscription, or creates a new event — everybody can see that it’s happened, instantly. (And the same goes for new support cases, @replies on Twitter, cancellations, and a whole lot more besides).
We also post automated daily updates of our key company KPIs for our team each morning, which helps to improve overall transparency too.
Real-time milestones have helped our team to feel more connected with our product and users.
Friday beers + tech/product talks
On Fridays, work finishes at 5pm and we break for beers and tech talks.
Often, individual team members informally present what they’ve been working on that week, which is another great opportunity for everybody to keep in the loop of upcoming product changes and improvements.
Sometimes, there’s a more generic tech subject that somebody is interested in demonstrating. Occasionally, we end up in the pub instead. Either way, it’s a great tradition that’s fun, and helps to ensure our team winds down from the week effectively (and perhaps a little bit drunk).
Related: 10 open source technologies we use to build Mixlr

-
How we get the perfect shuffle for your playlist in the Mixlr app
We're hiring! Are you a developer who wants to work on interesting technical challenges with a small, passionate team here in London? For more information, visit the Mixlr jobs homepage.
Playlist shuffle was a feature added to the Mixlr desktop app in 2015 after popular demand from users. Shuffling can be approached in different ways from a technical perspective, but is hard to get “right” from a user perspective. Youtube solves the problem by randomly sorting the playlist, which may be fine for a youtube listener playlist, but a Mixlr broadcaster probably wouldn’t want their lists being randomly rearranged. If you can think back to the way Winamp performed with shuffled tracks in a playlist, you may have had an experience where one of your favourite tracks never seemed to play.
At Mixlr, we wanted to nail the user experience for shuffling, using a high quality (in terms of bias) algorithm/technique. The shuffle feature was well received, and we would like to share our method for both learning and re-use; please read on for the juicy details.
Getting the shuffle right
Writing an algorithm to perform a shuffle, at first thought, sounds quite easy. A quick solution might involve selecting a random number from \(1\) to \(N\) (where \(N\) is the number of tracks you have loaded in your playlist) and choosing that track to play. This process could simply be repeated to select the next track. Sounds OK in principle, but it’s not actually a good solution for several reasons:
- The shuffle is biased, in the worst case it could result in one track being played more than others, whilst another track never gets played.
- Each track has a fixed (and biased!) probability of playback. That means there’s a possibility that one track could be selected multiple times in a row.
- There is no control over the probability - i.e. to manipulate the selection likelihood of a particular track
There are algorithms available for shuffling that solve the biasing issue (e.g. the Fisher-Yates-Knuth shuffle). However, we want more control over the shuffle to subjectively increase the quality of track playback order from a human perspective.
The shuffle experience
Shuffling in a way that “feels right” is a challenge in and of itself; having a intuitive user experience would have to inform algorithm design. There were certain requirements:
- Randomness - a proper random selection rather than a playlist sort. Because it feels more authentically random if you hear a track repeated in a short period.
- Controlling repetition - yes we want randomness, but not to the point of annoyance. It should be much less likely (but still possible) to hear the same track repeated in a short period.
- All tracks matter - if we have \(N\) tracks, and \(N - 1\) different tracks have played, it should be much more likely to select the track \(T_j\) which hasn’t played, rather than the previously selected track \(T_{\mu}\).
These requirements mean that this problem is different to shuffling a pack of cards. We need to assign and compute the probability of each track playing and make a random selection based on all probabilities (i.e. a type of stochastic roulette wheel selection).
Shuffling using random sampling
Random sampling is a method that is straightforward to understand and implement. The general idea behind random sampling to select individuals of a population using random numbers; in our case we have a population of tracks. Our approach differs from simple random sampling as we assign a propensity (weighted probability) to each track which is modified when a track is played (set to zero) but slowly increases over time. This form of selection requires us to record the sum of the propensity of all tracks \(P_{total}\) and multiply it by a random number \(r_1\) in the range \([0.0, 1.0]\) to generate a “target propensity” \(P_{target}\). Note that we recommend using the Mersenne Twister psuedo-random number generator, it has a period that far exceeds the requirements of this application yet is computationally inexpensive.
$$P_{total} = \sum_{i=1}^NP_i(T)$$ $$T_{\mu} = \min\left\{\mu|\sum_{j=1}^{j=\mu} a_j(x) > r_1P_{total}(x)\right\}$$ Using \(P_{target}\) we can select an individual track by assessing its “position” in the list of tracks propensities (by summing propensities until we hit the target).
Here are the major stages to our approach:
- Assign every track a propensity - in our case start the integer \(N\) (where \(N\) is total the number of tracks).
- Pick a random number \(r_1\) in the range \([0.0, 1.0]\) and multiply it by the total track propensities \(P_{total}\) to get a “target propensity” \(P_{target}\).
- Iterate over tracks and sum propensities until \(P_{target}\) is reached - select the last track \(T_{\mu}\) we iterated over to play.
- Reduce the propensity of the last track \(T_{\mu}\) we played - in our case we set it to \(0\).
- Update the propensities of any other tracks that are less than \(N\) (i.e. ones that have been recently played) - in our case we add \(1\).
- Recalculate the total propensity \(P_{total}\) of all tracks.
- GOTO 2.
This method satisfies the requirements of our shuffle experience: it provides good quality randomness, limits repetition and increases the likelihood of a previously unheard track getting airtime.
-
Five ways to use Slack part one: Jenkins CI
Slack found its way into many startups where it is not only celebrated as a convenient communication tool. At Mixlr we try to utilize our tool chains not only to increase productivity but to make our whole work environment more fun. In order to really grasp the potential of Slack you need to experience and try it out. In this series we want to show you how we at Mixlr use Slack beyond its pure chat functionality.
What is Slack?
Slack is a team messaging app for synchronous and asynchronous communication across different devices. Above all it is a tool which might seem simple at first glance but becomes powerful by adding integrations that knit tightly with your workflow.
Rather than just a collection of chat rooms it can be better described as a communication hub. Different channels can represent different teams, different topics or a very specific type of information that should stream into that particular channel.
What is Jenkins CI?
Jenkins is an open source continuous integration tool written in Java and arguably the most widely used one as well. Jenkins supports distributed agents and a build process. What you can do with Jenkins depends on your imagination due to its freedom of configuration and plethora of available plugins. A job, respectively project, can represent different things in Jenkins: compilation of a particular piece of software, running your unit tests or deploying to your production environment as soon as certain conditions are met. Jenkins offers a rich API to report back any details which makes it possible to utilize these information.
Jenkins and Slack at Mixlr
Writing tests with every new piece of function added to our back or front end is an essential part of the workflow at Mixlr. Our tests already cover the core functionality of our app. It is crucial that changes do not break any existing behavior as it could pottentially affect thousand of users. While it is nice to have these tests executing in a job in Jenkins CI and getting notified via email if somethings breaks it is not exactly as transparent or live as it could be.
We build a small addition to the existing Jenkins integration to give us more detail as soon as something is pushed to the repository or changed. No matter if master branch or feature branch, we are quite happy and used to the following view in our Slack #dev channel:
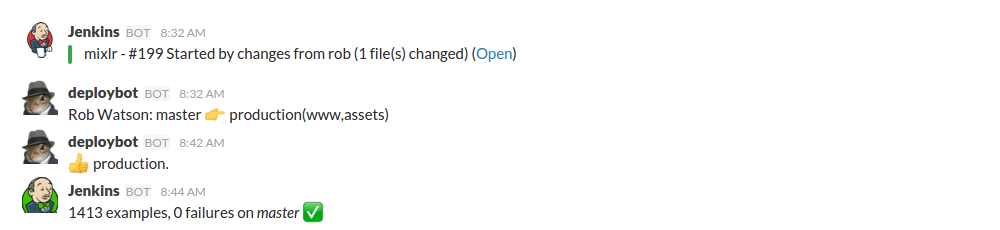
Although admittedly we all slip and fall sometimes. If that happens we would see something like that:
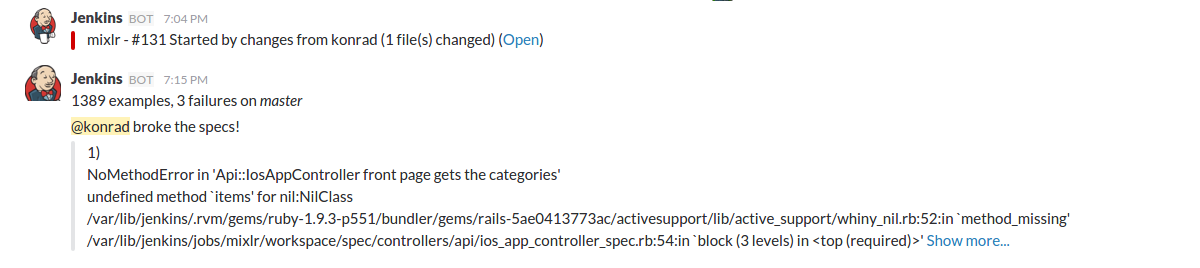
Unexpected failure can always occur. Though it is crucial that when something fails it will definitely not get pushed back but tackled immediately by our team. We enjoy contributing to a code base for which all of us take ownership. Increasing visibility also helps us to keep in mind that everyone at Mixlr is acting in concert and from time to time also a good laugh in the office when you just did not see that push breaking someone else’s tests.
-
We're hiring
We’re currently hiring for a number of roles, including:
- Backend Developer
- Frontend Developer
- Community Manager
All these roles are full-time, permanent and based at Mixlr HQ at Netil House, nestled in the heart of East London. You’ll be joining our small, friendly and focused team and building the world’s biggest audio broadcasting service.
For more information and a full list of current opportunities, visit our jobs page. And we’d love to hear from you too - drop us a line via http://mixlr.com/help/contact.

-
10 open source technologies we use at Mixlr
We're hiring. If you're a backend developer who is passionate about building rock-solid, high-availability systems using open source technology, you may find Mixlr to be a great team to join. Visit the Mixlr jobs homepage.
We rely on a host of amazing open source technologies to build the Mixlr platform. This post offers an overview of some of our favourite examples, and why they play such a big part in building our service.
PostgreSQL
PostgreSQL has been our main database since we migrated away from MySQL in early 2015.
Our experiences with Postgres so far have been very positive, especially bearing in mind that after five years of running a fast-growing startup we have a lot of data to deal with.
Even when working with tables containing hundreds of millions of rows, Postgres allows us to continue carrying out many routine administration tasks - such as adding or removing columns or building indexes - without locking tables and forcing our service offline. This is an area that MySQL in particular is notoriously deficient in, and had previously caused our development team numerous pulsating headaches.
Postgres has other advantages too: helpful
EXPLAINoutput, advanced constraints and a host of custom cell types for modelling data like IP addresses, JSON and complex container types, to name but a few.Redis
This fast, stable and elegant example of open source software powers many things at Mixlr. From acting as a short-term caching layer a la Memcached, storing sessions for our web application, or acting as a pubsub server delivering real-time messages to tens of thousands of client applications - it just works.
If there’s one thing not to love about Redis, it’s just a little bit too versatile. As with Maslow’s hammer, there is a tendency for everything to start to look like a candidate for storing or processing in Redis - even when there are better options for data persistence readily available. For this reason, we are careful to never put data into Redis that we wouldn’t be too unhappy to lose without warning.
The Redis source code is regularly hailed as an example of concise, well-written C.
Nginx
Nginx has quickly usurped Apache to become the most popular front-end web server in the world. It is also responsible for serving almost every HTTP request received by the Mixlr website, API and backend services.
Its event-driven design makes serving static files, assets and images incredibly pain-free.
And its modular configuration system allow us to easily optimise, secure and otherwise polish every part of our website and API.
Let’s not forget its integration with the Lua scripting language, discussed more below.
Haproxy
Sticking with HTTP processing tools, The Haproxy loadbalancer is another essential part of our infrastructure.
Although Nginx provides some duplicate functionality, Haproxy’s low-level and fine-grained configurability allow us to make the most of a relatively small pool of backend Ruby on Rails servers. This avoids most unnecessary backlogs forming when proxying requests, meaning our users are much more likely to be served the content they want as quickly as possible.
And of course a smaller pool of backend servers saves us a bunch of money and time too.
Much like Redis, it’s also another great example of a highly efficient, elegant tool that just works.
- Haproxy homepage
- Stackoverflow update: 560M page views a month, it’s all about performance
- Back to top
Lua
Lua is a compact, powerful (and characterful) scripting language. It’s so small that it’s become a de facto choice for embedded systems, making appearances in many games and industrial software packages.
For Mixlr, its allure is in its ability to be embedded in the Nginx web server. Lua code can be triggered at numerous points of the Nginx request/response cycle, giving us arbitrary programmatic access to the entire Nginx environment (not to mention external HTTP services, Redis, and more).
The possibilities here are clearly many - others have even implemented entire web application frameworks using Nginx and Lua.
We don’t go quite that far, but we do make use of Lua to further fine-tune our HTTP services, implement advanced page-caching strategies, and a lot more besides.
Puppet
Mixlr would likely not exist in its current form today if it wasn’t for Puppet. We use the configuration management system to define each and every one of our backend servers: what software and updates are installed, the location and content of configuration files, cron jobs, iptables rules, and lots more besides.
The value of Puppet comes in the time we save each time we deploy a new server. Instead of a day of manual and error-prone effort, spinning up a new box typically takes just minutes - and is repeated precisely, each and every time.
Unlike alternative Chef, Puppet has a declarative approach to configuration - a limitation we’ve found has actually been a positive influence in keeping our Puppet manifests simple and easy to understand.
Puppet is also at the heart of our autoscaling systems, allowing our service to respond quickly and automatically to unexpected spikes in traffic.
Ruby
Hailing from Japan, the popularity of the Ruby programming language has exploded over the last decade, mostly powered by its adoption by web developers across the world.
Ruby deserves being appreciated as a great open source project in its own right, however. The brainchild of Yukihiro Matsumoto - aka Matz - it is slightly idiosyncratic in style, infinitely flexible and - in the right hands - a profoundly powerful tool that’s also relatively easy to learn.
One of Ruby’s most distinguishing features is its aptness for creating domain-specific languages - small, specialised and efficient interfaces to sub-parts of a particular software system or application. At Mixlr we’ve used Ruby to build a DSL which defines our internal API, for example.
Ruby code also glues most of the Mixlr backend infrastructure together, its transparent interoperability with kernel and shell level functionality making it a great fit.
Ruby on Rails
The world’s most opinionated web framework powers Mixlr’s website, API and internal tools.
Rails turns building web applications into an incredibly productive pursuit, helped by its preference for convention over configuration - meaning the days of endless XML configuration files are thankfully (largely) behind us.
And then there’s the small matter of an active and highly passionate community, and a huge library of third party libraries, aka gems, to make development easier.
NodeJS
NodeJS burst into life in 2009, when Ryan Dahl got tired of trying to do non-blocking I/O in Ruby and decided to write his own JavaScript-based, C++-powered event-driven network programming framework.
Perfect for building low-latency, high-performance systems, we use NodeJS in two main applications: powering our real-time messaging services (which provide chat and other social features on Mixlr, amongst many other jobs) and also in a suite of custom audio streaming servers.
The power and flexibility of NodeJS means it will likely play a big role in the future of our infrastructure.
Jenkins
One of the most recent additions to this collection, Jenkins is an “open source automation server” - also known as a continuous integration tool. Like many others, we use Jenkins to automate the running of unit and functional tests on our main Rails applications.
Jenkins makes it possible to automatically trigger a full test run every time one of our development team pushes a new change to GitHub. This simple but poweful behaviour, combined with clever integration with Slack, has profoundly increased the usefulness of the tests by making it impossible for anybody to not know they are failing.
Watch this space for more information about the impact Jenkins has been having on our daily workflow.
Next…?
We’re hiring backend developers, and you soon be adding to this list yourself. Interested? Visit the Mixlr jobs homepage to find out more.
-
How to make CSRF protection work with page caching
We're hiring! Are you a web developer who wants to work on interesting technical challenges with a small, passionate team here in London? We'd love to chat more: drop us a line via jobs@mixlr.com.
Here at Mixlr we are accustomed to building our service to work well in high-traffic scenarios. We also place a high premium on maintaining our users’ security and safety. But what happens when these two essential goals conflict with each other?
One example of this is maintaining CSRF protection whilst also benefitting from page caching. Here’s how we do it.
What is CSRF protection?
CSRF protection allows us to ensure our users do not become the victims of cross-site forgery attacks.
Here’s a simple example:
- You’re browsing the internet, while logged into your Mixlr account
- You inadvertedly visit a malicious or infected website
- The malicious site uses JavaScript to make a POST request to (for example) mixlr.com/comments - our endpoint for incoming chat messages.
With no CSRF protection, the malicious site only has to figure out the format to POST the data. No authentication is required, because your browser will helpfully include your mixlr.com session and login cookies with the request!
With no further user interaction required, the malicious site is hapilly posting one or more chat messages from your Mixlr account. (And doubtless “helping” the rest of our community with the location of dubious mens’ health shopping portals and the like.)
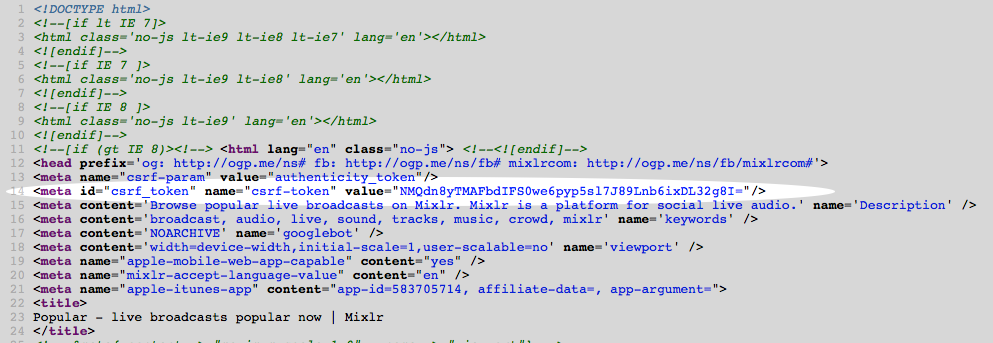
CSRF protection typically avoids this by including a hidden, secret value in every form submission. This value - the form authenticity token - is checked by the server before any non-GET request is processed. And because the malicious website could not know the value of a given user’s secret token, it renders this type of attack completely toothless.
What is page caching?
Page caching is a powerful way of increasing the scalability of your web service. It works on the premise that serving a static file - that is, a page of pre-rendered HTML markup - is likely to be profoundly faster than using a language like PHP, Ruby or Python to generate the same content.
It turns out that this premise is an entirely valid one - as a rule, cutting out the roundtrip to backend web servers, database, et al allows us to serve many hundreds times more concurrent page views than we’d be able to without page caching.
The limitation with page caching is the obvious one. As we’re short-circuiting the backend web servers, it’s only good for non-dynamic content - that is, content you’re prepared to be served without modification to every user, whether they’re logged in or not.
#### Why CSRF protection and page caching clash
Which leads us nicely onto why these two desirable technologies don’t work well together.
CSRF protection requires a unique-per-user token to be included in each page. But page caching makes this, at least on the surface, impossible - because dynamic content in each page cannot be achieved.
Option 1: Server-side includes
For many years, we’ve embedded Lua into the Nginx server to help us to turbo-charge our deployments.
This also helped us make page caching and CSRF work together. Specifically, we made use of SSI, or server-side includes. These are effectively small templates which are injected by Nginx into every page - even cached ones.
With the help of some custom Lua code, which made a sub-request to a very fast, efficient Rails endpoint when required to fetch a new CSRF token, we were able to serve tens of thousands of cached responses every second - and include a unique CSRF token in each and every one.
While this solution was very clever and flexible, it came with some downsides too. Debugging Lua code at the Nginx level is difficult and counter-intuitive - and just having code at the Nginx/Lua level is a bit surprising too! It’s not the first place you think of checking when you’ve got a login/CSRF bug.
Furthermore, as we’ve incrementally improved our session management and authentication code, we’ve observed more and more bugs which were traced back to this code. So we went looking for a different approach.
Option 2: AJAX
Another option would be to not render a CSRF token in each page, but instead use JavaScript to make a background HTTP request and fetch the CSRF token after the page has loaded.
This would allow us to cache the main content on the page, but then trigger a background request to fetch the CSRF token for the user.
The advantage here is that it allows us to remove the custom Nginx/Lua code, and keep this essential functionality upfront and visible in our codebase. On the downside, there will be a delay after loading the page during which the user will be unable to successfully submit any forms. And if the request to fetch the CSRF token fails for some reason, any such form submissions will fail at least until the page is reloaded.
Our current solution
We want to avoid as much code at the Nginx level as possible, so we’ve made the call to remove our implementation of Option 1.
Additionally, we want to make our lives as easy as possible - so for all non-cached responses (that is - where the page generation is handled by our backend Rails servers) - we’re allowing the framework to take the strain. In these cases, we simply allow Rails’ built-in CSRF token helpers do the work, and render the token in the page for us.
How do we deal with page-cached responses? Firstly, we make sure that we don’t include the CSRF token when we’re caching a page.
And then in our controller, something like:
Now, Nginx will serve page-cached content with the invalid form authenticity token removed.
In our front-end code, we simply check to see if we’re missing a CSRF token - that is, if the page we’re on has been served from a static file - and if so, make a quick XHR request to pick up the token, populate the forms and set the session cookie.
Job done!
What’s next?
We’d love to hear your feedback, or suggestions for improvements to our approach. Drop us a line and let us know what you think!
-
Welcome to Mixlr Tech Blog
Welcome to the Mixlr technology blog, where we will be sharing some of what we learn every day while building Mixlr’s back-end and front-end systems and apps.
Right now, we’re hiring for Ruby on Rails, C/C++ and DevOps engineers here in London. If you want to find out more information, drop us a line.
